Working with 0 data, 0 scripts and 0 files
0 Data are test data that are initially required for the execution of the test. 0 Data can take many forms. It
can consist of, for example, persons with a name, address and other features that are used in various test cases. It
can also be the users who are permitted to use the system (the testers). Another form again is the data in socalled
master tables. It is important to identify and describe the required 0 data in the specification of the test
cases.
0 Scripts are test scripts with which the 0 data is placed in the system. This takes place via the regular
system functions, with the advantage that the functions of the system concerned are already being tested. An added
advantage is the clarity of the starting point/data (0 scripts are executed on an empty database). 0 Scripts are
executed fi rst, and therefore, with the execution, the tester can gain an initial impression of the quality of the
test object.
A condition for working with 0 scripts is of course that the functions required for inputting 0 data are built first.
If that is not the case, it may be decided to work with socalled 0 files. These files contain the 0 data and
can be read into the database direct via separate front-end software (e.g. based on SQL).
Test data in data-warehouse testing
A data warehouse can be generally split into two groups of programs:
-
The extraction and conversion programs for fi lling the data warehouse
-
The reporting programs for obtaining information from the data warehouse.
While it is preferable to use separate test data for testing individual extraction and conversion programs, production
data are inclined to be used with integral testing of the reporting programs. The reason for this is that the creation
of a consistent set of fi ctional test data is demanding and with a set of production data, this consistency is almost
automatically guaranteed. Besides, a big advantage is that a user can assess the outcome of a report more easily when
using real production data.
Disadvantages of using production data in testing a data warehouse, however, are:
-
The difficulty of making exact output predictions, since it is difficult to find out what the input was
-
The confidentiality associated with some data. In practice, this means that the use of production data is not
possible, or only after application of scrambling techniques (depersonalisation, making data unrecognisable)
-
The continually changing situation: the production data of today are different from those of a week ago, which
hampers retesting.
This last disadvantage can be helped by suspending the daily/weekly reloading of data, so that the same starting point
can always be used. An applied simplification is not taking the entire production files, but a selection of them.
However, this requires focus (and time) for the mutual consistency of the data.
Delta test1
As an addition to this, the following procedure may be gone through:
-
Take a subset of production data and call this X
-
Run subset X in its entirety through the data warehouse and record the results
-
Now add to subset X a number of self-created test cases and call this set X+1.
-
Run subset X+1, too, in its entirety through the data warehouse
-
The results of X+1 can be predicted by adding to the results of X the same selfcreated test cases
-
Then add test cases to subset X+1 and call this X+2
-
Run subset X+2 in its entirety through the data warehouse
-
The results of X+2 can be predicted by adding the self-created test cases to the results of X+1 (this second run is
useful for checking changes in time).
Delta test2
The following is a somewhat simpler variant of the above:
-
Empty the database(s) of the delivering systems
-
Put a number of self-specified test cases into these systems
-
Run the extraction and check the result in the data warehouse
-
Now put the same test cases as a kind of regression test into the full database(s) of the delivering systems
-
Run the extraction and check the result (of the test cases) in the data warehouse.
Example
For a test process in a big data warehouse, the following test files are used as test data:
-
The small test set: this is as small a test file as possible, with which the, possibly obvious, functional problems
in the use of the prototype are searched for effectively. This test set is used as the first test after the
development or reworking of the prototype and with all the other tests to quickly obtain an impression.
-
The 1,000-records test file is used for the functional acceptance test and consists of around 1,000 records from a
daily file. The daily file that is used for this should concern a day in which as many (problem-generating)
different cases occur. The choice of this is determined together with the client.
-
The 5% (or X%) test set is a representative sample compiled by the client from the source files for the third
increment.
-
The ‘daily files’ test set consists of a complete daily file. The daily file that is used for this should concern a
day in which as many (problem-generating) different cases as possible occur. The choice of this is determined
together with the client. The execution of a weekly process in order to check whether starting status + mutations =
fi nal status is an important point of focus here. Preliminary dates of Wednesday 1 March, Thursday 2 March and
Friday 3 March are used, after which a weekly process is run to check this.
Example of cumulative construction of the central starting point
For the testing of a mobile telephone subscription billing system, a test team of 5 persons was involved. Each of these
individuals was responsible for the testing of a specific subsystem. In order to avoid the testers getting in each
other’s way when using the central starting point, it was proposed to link a range of telephone numbers to each
subsystem. The starting point of the test cases for a specific subsystem then had to fall within that range. A range
was also agreed for the integral test that ran across the various subsystems. This resulted in the following division:
Subsystem 1: range of telephone numbers +31610000000 to +31619999999
Subsystem 2: range of telephone numbers +31620000000 to +31629999999
Subsystem 3: range of telephone numbers +31630000000 to +31639999999
Subsystem 4: range of telephone numbers +31640000000 to +31649999999
Subsystem 5: range of telephone numbers +31650000000 to +31659999999
Integral: range of telephone numbers +31690000000 to +31699999999
Test environments and test data within SAP®
The terminology of SAP speaks of a system landscape, containing the various environments. A system landscape often
consists of separate development, test, acceptance and production environments (also known as DTAP). These environments
are called clients. There can be several clients per environment (instance) present. Several clients ensure that the
testers do not get in each other’s way as regards test data. It is advisable to set up a separate master client to
secure the test data. Through copying, these data can be placed in another client. SAP also has the Test Data Migration
Server tool, with which data from a productive environment can be reduced and if necessary anonimised and transferred
to non-productive environments.
The transferring of changes (customising, new software) in SAP from one environment to another is done by means of
so-called transports (SAP Transport
Management System). Transporting can be client-dependent or client-independent. With transporting, it is necessary to
maintain a certain sequence and it is sometimes necessary to create certain settings manually per environment. All of
this requires very good confi guration management containing release or transport administration.
Figure 1 contains an illustrated example of the environments and associated transports.
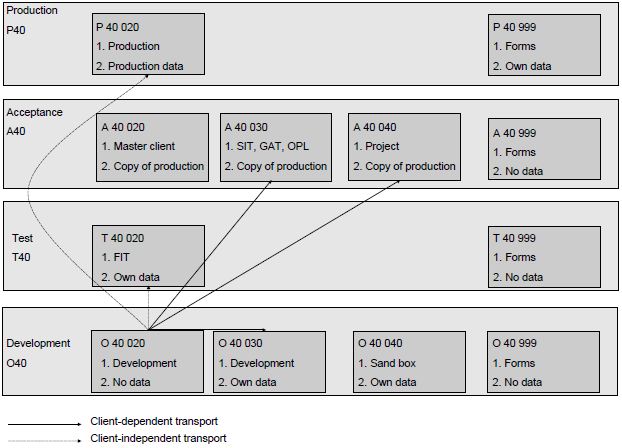
Figure 1: SAP environments and transports
|
